
tl;dr Succinct is a distributed data store that supports a wide range of point queries (e.g., search, count, range, random access) directly on a compressed representation of the input data. We are very excited to release Succinct as an Apache Spark package, that enables search, count, range and random access queries on compressed RDDs. This release allows users to use Apache Spark as a document store (with search on documents) similar to ElasticSearch, a key value interface (with search on values) similar to HyperDex, and an experimental DataFrame interface (with search along columns in a table). When used as a document store, Apache Spark with Succinct is 2.75x faster than ElasticSearch for search queries while requiring 2.5x lower storage, and over 75x faster than native Apache Spark.
Succinct on Apache Spark Overview
Search is becoming an increasingly powerful primitive in big data analytics and web services. Many web services support some form of search, including LinkedIn search, Twitter search, Facebook search, Netflix search, airlines, hotels, as well as services specifically built around search — Google, Bing, Yelp, to name a few. Apache Spark supports search via full RDD scans. While fast enough for small datasets, data scans become inefficient as dataset become even moderately large. One way to avoid data scans is to implement indexes, but can significantly increase the memory overhead.
We are very excited to announce the release of Succinct as an Apache Spark package, that achieves a unique tradeoff — storage overhead no worse (and often lower) than data-scan based techniques and query latency comparable to index-based techniques. Succinct on Apache Spark enables search (and a wide range of other queries) directly on compressed representation of the RDDs. What differentiates Succinct on Apache Spark is that queries are supported without storing any secondary indexes, without data scans and without data decompression — all the required information is embedded within the compressed RDD and queries are executed directly on the compressed RDD.
In addition, Succinct on Apache Spark supports random access of records without scanning the entire RDD, a functionality that we believe will significantly speed up a large number of applications.
An example
Consider a collection of Wikipedia articles stored on HDFS as a flat unstructured file. Let us see how Succinct on Apache Spark supports the above functionalities:
// Import relevant Succinct classes import edu.berkeley.cs.succinct._ // Read an RDD as a collection of articles; sc is the SparkContext val articlesRDD = ctx.textFile("/path/to/data").map(_.getBytes) // Compress the input RDD into a Succinct RDD, and persist it in memory // Note that this is a time consuming step (usually at 8GB/hour/core) since data needs to be compressed. // We are actively working on making this step faster. val succinctRDD = articlesRDD.succcinct.persist() // SuccinctRDD supports a set of powerful primitives directly on compressed RDD // Let us start by counting the number of occurrences of "Berkeley" across all Wikipedia articles val count = succinctRDD.count("Berkeley") // Now suppose we want to find all offsets in the collection at which “Berkeley” occurs; and // create an RDD containing all resulting offsets val offsetsRDD = succinctRDD.search("Berkeley") // Let us look at the first ten results in the above RDD val offsets = offsetsRDD.take(10) // Finally, let us extract 20 bytes before and after one of the occurrences of “Berkeley” val offset = offsets(0) val data = succinctRDD.extract(offset - 20, 40)
Many more examples on using Succinct on Apache Spark are outlined here.
Performance
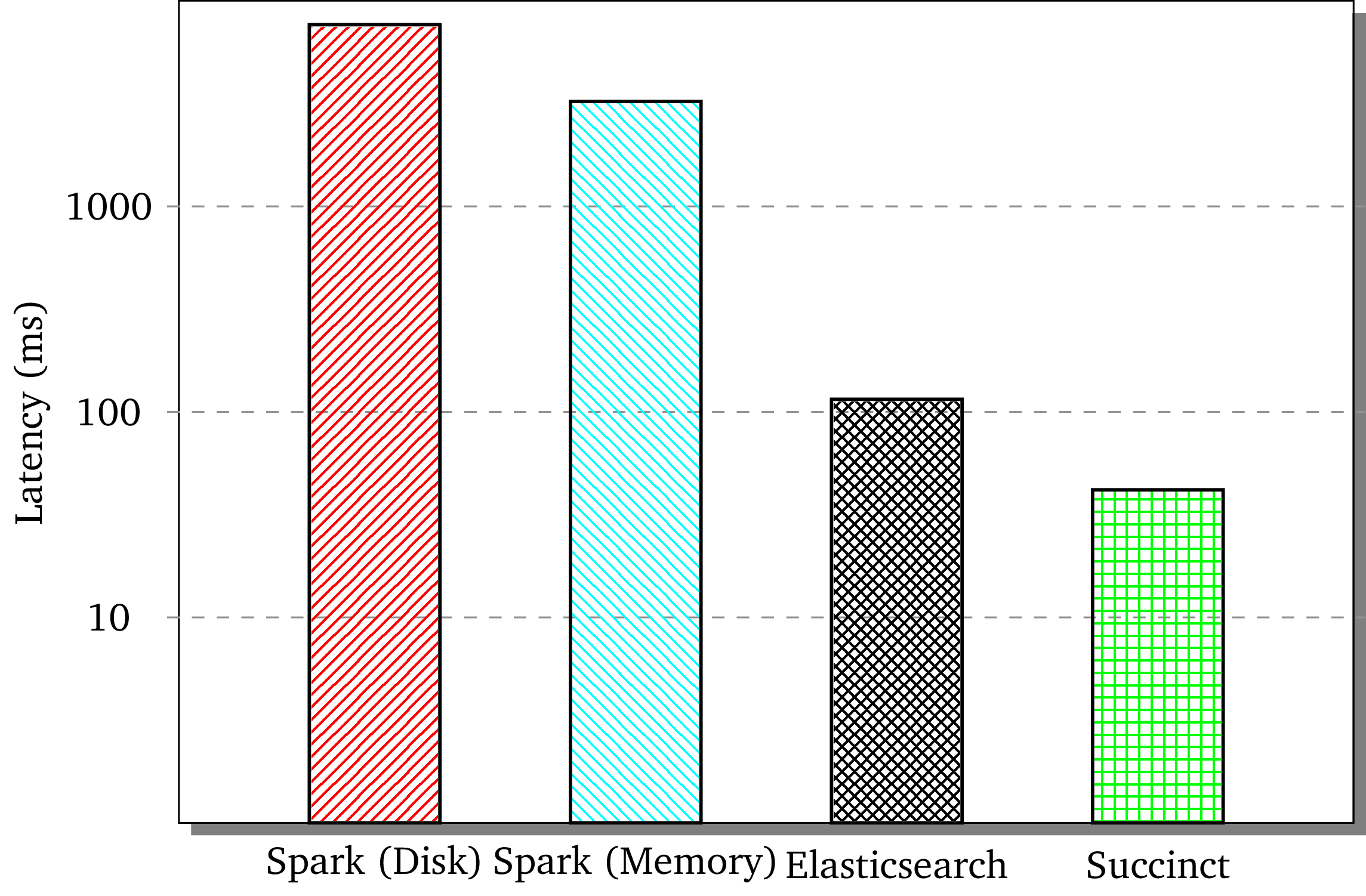
The figure compares the search performance of Apache Spark with Succinct against ElasticSearch and native Apache Spark. We use a 40GB collection of Wikipedia documents over a 4-server Amazon EC2 cluster with 120GB RAM (so that all systems fit in memory). The search queries use words with varying number of occurrences (1–10,000) with uniform random distribution across 10 bins (1–1000, 1000-2000, etc). Note that the y-axis is on log scale.
Interestingly, Apache Spark with Succinct is roughly 2.75x faster than Elasticsearch. This is when ElasticSearch does not have the overhead of Apache Spark’s job execution, and have all the data fit in memory. Succinct achieves this speed up while requiring roughly 2.5x lower memory than ElasticSearch (due to compression, and due to storing no additional indexes)! Succinct on Apache Spark is over two orders of magnitude faster than Apache Spark’s native RDDs due to avoiding data scans. Random access on documents has similar performance gains (with some caveats).
Below, we describe a few interesting use cases for Succinct on Apache Spark, including a number of interfaces exposed in the release. For more details on the release (and Succinct in general), usage and benchmark results, please see Succinct webpage, the NSDI paper, or a more detailed technical report.
Succinct on Apache Spark: Abstractions and use cases
Succinct on Apache Spark exposes three interfaces, each of which may have several interesting use cases. We outline some of them below:
- SuccinctRDD
- Interface: Flat (unstructured) files
- Example application: log analytics
- Example: one can search across logs (e.g., errors for debugging), or perform random access (e.g., extract logs at certain timestamps).
- System with similar functionality: Lucene
- SuccinctKVRDD
- Interface: Semi-structured data
- Example application: document stores, key-value stores
- Example:
- (document stores) search across a collection of Wikipedia documents and return all documents that contain, say, string “University of California at Berkeley”. Extract all (or a part of) documents.
- (key-value stores) search across a set of tweets stored in a key-value store for tweets that contain “Succinct”. Extract all tweets from the user “_ragarwal_”.
- System with similar functionality: ElasticSearch
- (An experimental) DataFrame interface
- Interface: Search and random access on structured data like tables
- Example applications: point queries on columnar stores
- Example: given a table with schema {userID, location, date-of-birth, salary, ..}, find all users who were born between 1980 and 1985.
- Caveat: We are currently working on some very exciting projects to support a number of additional SQL operators efficiently directly on compressed RDDs.
When not to use Succinct on Apache Spark
There are a few applications that are not suitable for Succinct on Apache Spark — long sequential reads, and search for strings that occur very frequently (you may not want to search for “a” or “the”). We outline the associated tradeoffs on Succinct webpage as well.
Looking Ahead
We at AMPLab are working on several interesting projects to make Succinct on Apache Spark more memory efficient, faster and more expressive. To give you an idea about what is next, we are going to close this post with a hint on our next post: executing Regular Expression queries directly on compressed RDDs. Stay tuned!