We are happy to announce Splash: a general framework for parallelizing stochastic learning algorithms on multi-node clusters. If you are not familiar with stochastic learning algorithms, don’t worry! Here is a brief introduction to their central role in machine learning and big data analytics.
What is a Stochastic Learning Algorithm?
Stochastic learning algorithms are a broad family of algorithms that process a large dataset by sequential processing of random subsamples of the dataset. Since their per-iteration computation cost is independent of the overall size of the dataset, stochastic algorithms can be very efficient in the analysis of large-scale data. Examples of stochastic algorithms include:
- Stochastic Gradient Descent (SGD)
- Stochastic Dual Coordinate Ascent (SDCA)
- Markov Chain Monte Carlo (MCMC)
- Gibbs Sampling
- Stochastic Variational Inference
- Expectation Propagation.
Stochastic learning algorithms are generally defined as sequential procedures and as such they can be difficult to parallelize. To develop useful distributed implementations of these algorithms, there are three questions to ask:
- How to speed up a sequential stochastic algorithm via parallel updates?
- How to minimize the communication cost between nodes?
- How to design a user-friendly programming interface for Spark users?
Splash addresses all three of these issues.
What is Splash?
Splash consists of a programming interface and an execution engine. You can develop any stochastic algorithm using the programming interface without considering the underlying distributed computing environment. The only requirement is that the base algorithm must be capable of processing weighted samples. The parallelization is taken care of by the execution engine and is communication efficient. Splash is built on Apache Spark, so that you can employ it to process Resilient Distributed Datasets (RDD).
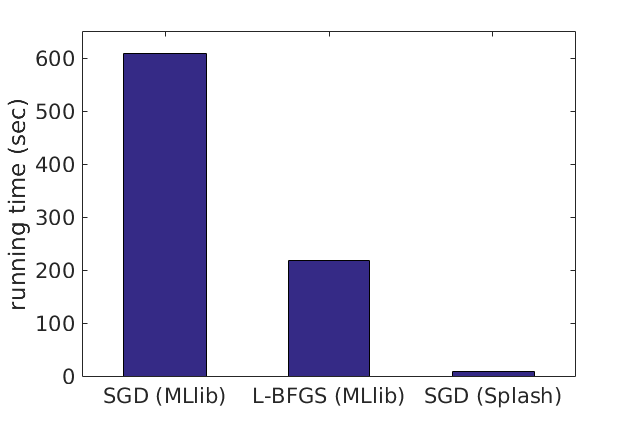
On large-scale datasets, Splash can be substantially faster than existing data analytics packages built on Apache Spark. For example, to fit a 10-class logistic regression model on the mnist8m dataset, stochastic gradient descent (SGD) implemented with Splash is 25x faster than MLlib’s L-BFGS and 75x faster than MLlib’s mini-batch SGD for achieving the same accuracy. All algorithms run on a 64-core cluster.
To learn more about Splash, visit the Splash website or read our paper. You may also be interested in the Machine Learning Packages implemented on top of Splash. We appreciate any and all feedback from early users!