
Data Drives Decisions
Today, more and more organizations collect more and more data, and they do so with one goal in mind: extracting value. In most cases, this value comes in the form of decisions. There are myriad examples of data driving decisions: (1) monitoring network traffic to detect and defend against a cyber attack, (2) using clinical and genomic data to provide personalised medical treatments, (3) mining system logs to diagnose SLA violations and optimize the performance of large scale systems, (4) analyzing user logs and feedback to decide what ads to show.
While making decisions based on this huge volume of data is a big challenge in itself, even more challenging is the fact that the data grows faster than the Moore’s law. According to one recent report, data is expected to grow 64% every year, and some categories of data, such as the data produced by particle accelerators and DNA Sequencers, grow much faster.# This means that, in the future, we will need more resources (e.g., servers) just to make the same decision!
Approximate Answers, Sampling, and Moore’s Law
Our key insight in addressing the challenge of data growing faster than the Moore’s is that decisions do not always need exact answers. For example, to detect an SLA violation of a web service, we do not need to know exactly the value of the quality metric (e.g., response time); we need only to know that this value exceeds the SLA. In many instances, approximate answers are good enough as long as they are small and bounded.
And there is another strong reason why approximate answers make sense. Even if computations are exact, they cannot always guarantee perfect answers. This is simply because data inputs are often noisy. Today, many inputs are either human-generated and uncurated (e.g., user logs, tweets, comments on social networks) or they come from sensors that exhibit inherent measurement errors (e.g., thermometers, scales, DNA sequencers, etc). This means that if we can bound computation error to much smaller than the input error, this won’t affect answer’s quality.
Accommodating approximate answers allows us to run the computations on a sample of the input data, instead of on the complete data. This is important since typically the computation error depends on the sample size, and not on the input size. In particular, the standard error of many computations is inversely proportional to S, where S is the sample size (assuming the sample is i.i.d). This means that the growth of the data is no longer a challenge. Indeed, even if the data grows faster than the Moore’s law, the error of the computation is actually decreasing (see Figure below).
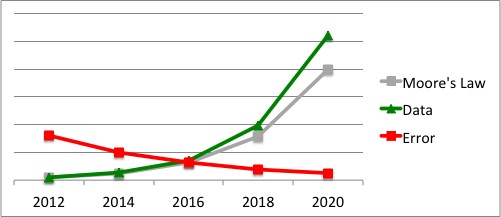
This is simply because Moore’s law allows us to process bigger and bigger samples, which means smaller and smaller errors. In particular, Moore’s law allows us to halve the error every three years.
Thus, accommodating approximate answers, can change the way we can think about big data processing. Indeed, in this context, Moore’s law can allow us to either
- Improve the accuracy of the computation;
- Compute the same result faster;
- Use the extra cycles to improve the analysis, possibly by developing and running new analytics tools, or using more features in the datasets.
Challenges in Approximate Big Data Processing
Of course, supporting error bounded computations comes with its own challenges. Arguably the biggest one is to compute error bounds. While this is relatively easy for aggregate operators, such as sum, count, average, and percentiles, it is far from trivial for arbitrary computations. One possibility would be to use Bootstrap, a very general and powerful technique that allows one to compute the error for functions that are Hadamard differentiable. However, this technique is very expensive (e.g., it requires to run the computations 100-200 times on samples of the same size as the original sample). Furthermore, verifying whether the function implemented by computation is Hadamard differentiable is far from trivial.
Within the AMPLab we are aiming to address these challenges by developing new algorithms and systems. Recently, we have developed Bag of Little Bootstraps (BLB), a new method to asses the quality of an estimator that has similar convergence properties as Bootstrap, but it is far more scalable. Currently, we are developing new diagnosis techniques to verify whether Bootstrap/BLB is “working” for a given computation, data distribution, and sample size. Finally, we are designing and developing BlinkDB, a highly scalable approximation query engine that leverages these techniques, as part of the Berkeley Data Analytics Stack (BDAS) stack.