
One of the AMP Lab’s goals is to bring interactive performance, similar to that available in smaller-scale databases, to Big Data systems, while retaining the flexibility and scalability that makes them compelling. To this end, we have developed Shark, a large-scale data warehouse system for Spark designed to be compatible with Apache Hive.
Our new tech report, Shark: SQL and Rich Analytics at Scale, describes Shark’s architecture and demonstrates how Shark executes SQL queries from 10 to over 100 times faster than Apache Hive, approaching the performance of parallel RDBMSs, while offering improved fault-tolerance, schema flexibility, and machine-learning integration.
Shark outperforms Hive/Hadoop on both disk- and memory-based datasets. As a sample result, we present Shark’s performance versus Hive/Hadoop on two real SQL queries from an early industrial user and one iteration of a logistic regression classification algorithm (results are for a 100-node EC2 cluster):
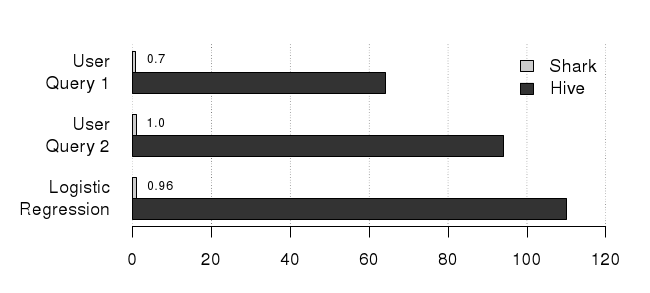
Query Time (seconds)
The full report features several other benchmarks, including micro-benchmarks using TPC-H data and real queries from the aforementioned industrial user.
Several innovative optimizations are behind these performance results, including
- In-Memory Columnar Storage, which stores data in a compressed, memory-efficient format,
- Partial DAG Execution, a technique that enables several runtime optimizations, including join algorithm selection and skew handling,
- Fine-grained fault-tolerance, which allows Shark to recover from mid-query failures within seconds using Spark’s Resilient Distributed Dataset (RDD) abstraction, and
- Efficient Parallel Joins, which are necessary when joining two or more large tables.
Looking ahead, we are currently implementing additional optimizations, such as byte-code compilation, which we believe will further improve performance.
Shark challenges the assumption that MapReduce-like systems must come at the cost of performance: it achieves performance competitive with traditional RDBMS systems, while retaining the fault tolerance, schema flexibility, and advanced programming models so core to the big data movement.
Shark is already in use today in a number of datacenters. If want to try Shark, you can find it at http://shark.cs.berkeley.edu. Also, be sure to join the Shark Users mailing list to join in the conversation and keep up with the latest developments.