
The vision of AMPLab is to integrate Algorithms (Machine Learning), Machines (Cloud Computing), and People (Crowdsourcing) together to make sense of Big Data. In the past several years, AMPLab has developed a variety of open source software components to fulfill this vision. For example, to integrate Algorithms and Machines, AMPLab is developing MLbase, a distributed machine learning system that aims to provide a declarative way to specify Machine Learning tasks.
One area we see great potential for adding People to the mix is Data Cleaning. Real-world data is often dirty (inconsistent, inaccurate, missing, etc.). Data analysts can spend over half of their time to clean data without doing any actual analysis. On the other hand, without data cleaning it is hard to obtain high-quality answers from dirty data. Crowdsourced data-cleaning systems could help analysts clean data more efficiently and more cheaply, which would significantly reduce the cost of the entire data analysis pipeline.
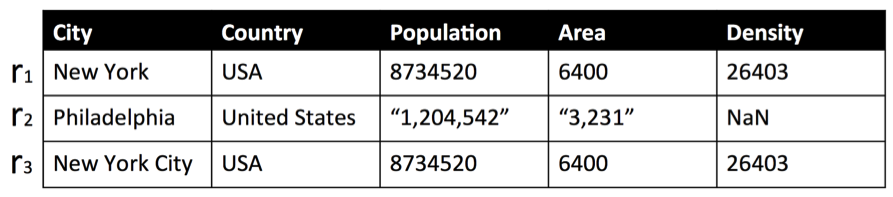
Table 1: An Example of Dirty Data (with format error, missing values, and duplicate values)
In this post, I will highlight two AMPLab research projects aimed in this direction: (1) CrowdER, a hybrid human-machine entity resolution system; (2) SampleClean, a sample-and-clean framework for fast and accurate query processing on dirty data.
![]()
Entity resolution (ER) in database systems is the task of finding different records that refer to the same entity. ER is particularly important when integrating data from multiple sources. In such scenarios, it is not uncommon for records that are not exactly identical to refer to the same real-world entity. For example, consider the dirty data shown in Table 1. Records r1 and r3 in the table have different text in the City Name field, but refer to the same city.
A simple method to find such duplicate records is to ask the crowd to check all possible pairs and decide whether each item in the pair refers to the same entity or not. If a data set has n records, this human-only approach requires the crowd to examine O(n^2) pairs, which is infeasible for data sets of even moderate size. Therefore, in CrowdER we propose a hybrid human-machine approach. The intuition is that among O(n^2) pairs of records, the vast majority of pairs will be very dissimilar. Such pairs can be easily pruned using a machine-based technique. The crowd can then be brought in to examine the remaining pairs.
Of course, in practice there are many challenges that need to be addressed. For example, (i) how can we develop fast machine-based techniques for pruning dissimilar pairs; (ii) how can we reduce the crowd cost that is required to examine the remaining pairs? For the first challenge, we devise efficient similarity-join algorithms, which can prune dissimilar pairs from a trillion of pairs within a few minutes; For the second challenge, we identify the importance of exploiting transitivity to reduce the crowd cost and present a new framework for implementing this technique.
We evaluated CrowdER on several real-world datasets, where they are hard for machine-based ER techniques. Experimental results showed that CrowdER achieved more than 50% higher quality than these machine-based techniques, and at the same time, it was several orders of magnitude cheaper and faster than human-only approaches.
![]()
While crowdsourcing can make data cleaning more tractable, it is still highly inefficient for large datasets. To overcome this limitation, we started the SampleClean project. The project aims to explore how to obtain accurate query results from dirty data, by only cleaning a small sample of the data. The following figure illustrates why SampleClean can achieve this goal.
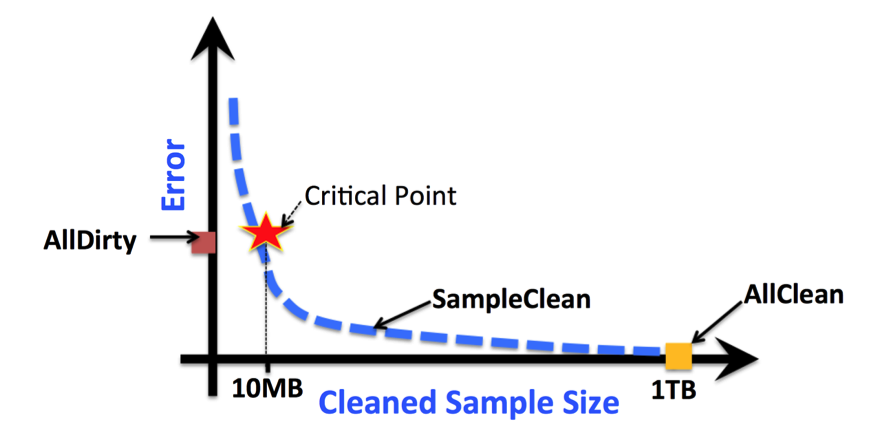
In the figure, we compare the error in the query results returned by three query processing methods.
- AllDirty does not clean any data, and simply runs a query over the entire original data set.
- AllClean first cleans the entire data set and then runs a query over the cleaned data.
- SampleClean is our new query processing framework that requires cleaning only a sample of the data.
We can see that SampleClean can return a more accurate query result than AllDirty by cleaning a relatively small subset of data. This is because SampleClean can leverage the cleaned sample to reduce the impact of data error on its query result, but AllDirty does not have such a feature. We can also see that SampleClean is much faster than AllClean since it only needs to clean a small sample of the data but AllClean has to clean the entire data set.
An initial version of the SampleClean system was demonstrated recently at AMPCamp 5 [slides] [video]. We envision that the SampleClean system can add data cleaning and crowdsourcing capabilities into BDAS (the Berkeley Data Analytics Stack), and enable BDAS to become a more powerful software stack to make sense of Big Data.
![]()
Crowdsourcing is a promising way to scale up the inefficient process of cleaning data in the data analysis pipeline. However, crowdsourcing brings along with it a number of significant design challenges. In this post, I introduce CrowdER and SampleClean, two AMPLab’s research projects aimed at addressing this problem. Of course, there is a wide range of other open challenges to be researched in this area. We have collected a list of recently published papers on related topics by groups around the world. Interested readers can find them at this link.