A major goal of the AMPLab is to provide high performance for data-intensive algorithms and systems at large scale. Currently, AMP has projects focusing on cluster-scale machine learning, stream processing, declarative analytics, and SQL query processing, all with an eye towards improving performance relative to earlier approaches.
Whenever performance is a stated goal, measuring progress becomes a critical component of innovation. After all, how can one hope to improve that which is not measured [1]?
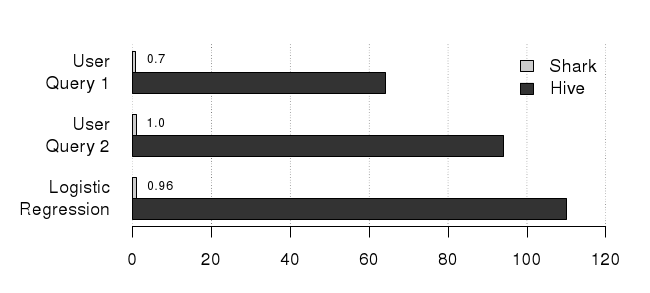
To meet this need, today we’re releasing a hosted benchmark that compares the performance of several large-scale query engines. Our initial benchmark is based on the well known 2009 Hadoop/RDMBS benchmark by Pavlo et al. It compares the performance of an analytic RDBMS (Redshift) to Hadoop-based SQL query engines (Shark, Hive, and Impala) on a set of relational queries.
The write-up includes performance numbers for a recent version of each framework. An example result, which compares response time of a high-selectivity scan, is given below:
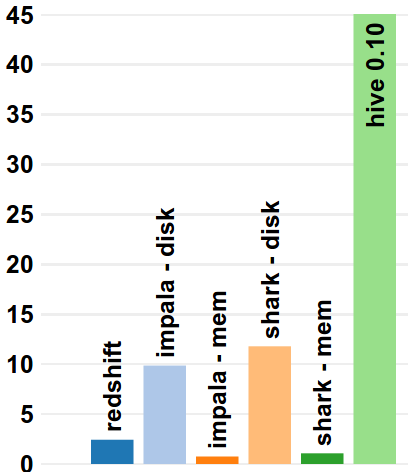
Because these frameworks are all undergoing rapid development, we hope this will provide a continually updated yardstick with which to track improvements and optimizations.
To make the benchmark easy to run frequently, we have hosted it entirely in the cloud: We’ve made all datasets publicly available in Amazon’s S3 storage service and included turn-key support for loading the data into hosted clusters. This allows individuals to verify the results or even run their own queries. It is entirely open source, and we invite people to fork it, improve it, and contribute new frameworks and updates. Over time, we hope to extend the workload to include advanced analytics like machine learning and graph processing.
One thing to keep in mind: performance isn’t everything. Capabilities, maturity, and stability are also very important; the best performing system may not be the most useful. Unfortunately, these other characteristics are also harder to measure!
We hope you checkout the benchmark, it is hosted on the AMP website and will be updated regularly.