

Recently at the AMP Lab, we’ve been focused on building application frameworks on top of the BDAS stack. Projects like GraphX, MLlib/MLI, Shark, and BlinkDB have leveraged the lower layers of the stack to provide interactive analytics at unprecedented scale across a variety of application domains. One of the projects that we have focused on over the last several months we have been calling “ML Pipelines”, an extension of our earlier work on MLlib and is a component of MLbase.
In real-world applications – both academic and industrial – use of a machine learning algorithm is only one component of a predictive analytic workflow. Pre-processing steps and considerations about production deployment must also be taken into account. For example, in text classification, preprocessing steps like n-gram extraction, and TF-IDF feature weighting are often necessary before training of a classification model like an SVM. When it comes time to deploy the model, your system must not only know the SVM weights to apply to input features, but also how to get your raw data into the same format that the model is trained on.
The simple example above is typical of a task like text categorization, but let’s take a look at a typical pipeline for image classification:
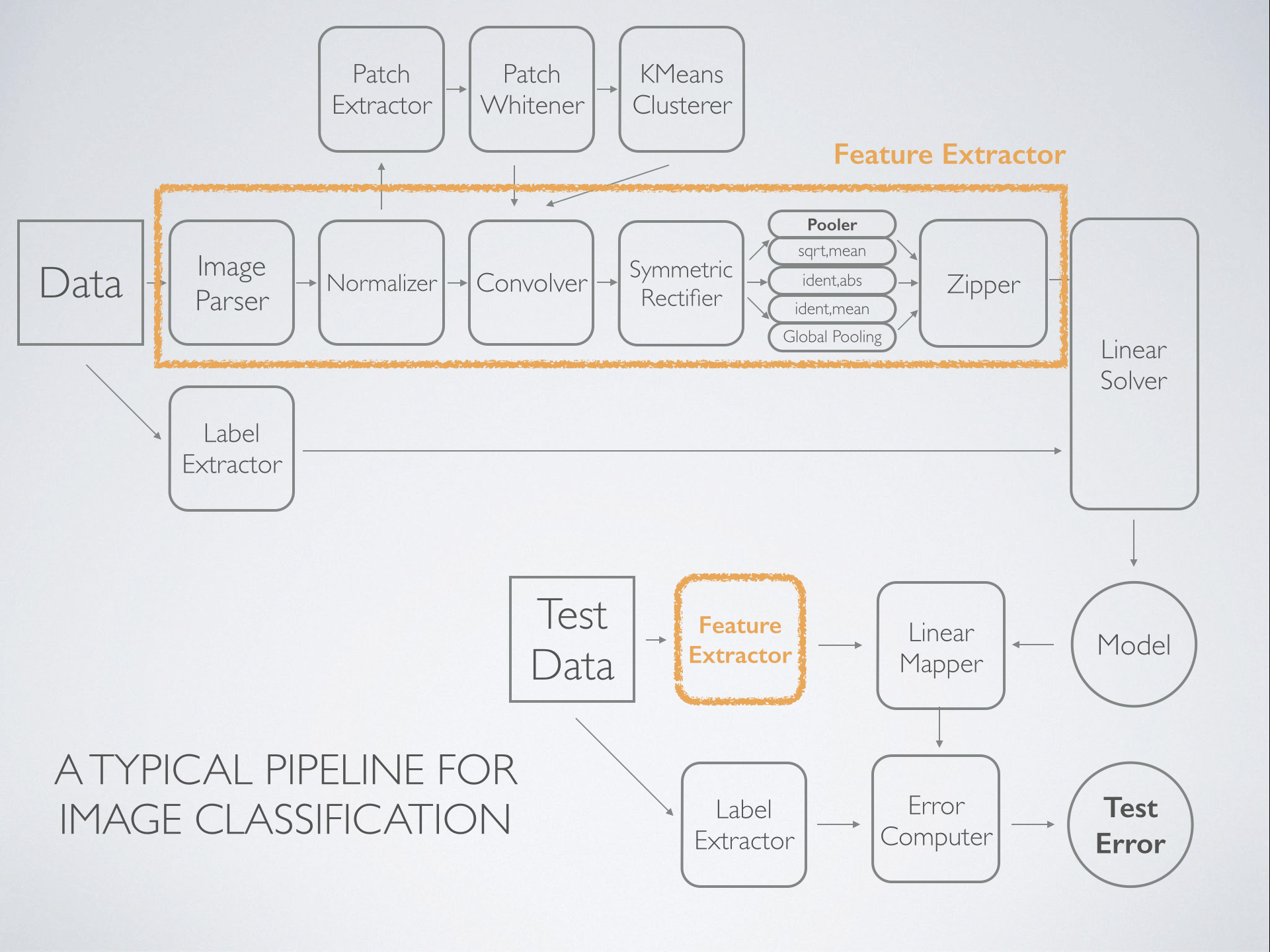
A Sample Image Classification Pipeline.
This more complicated pipeline, inspired by this paper, is representative of what is done commonly done in practice. More examples can be found in this paper. The pipeline consists of several components. First, relevant features are identified after whitening via K-means. Next, featurization of the input images happens via convolution, rectification, and summarization via pooling. Then, the data is in a format ready to be used by a machine learning algorithm – in this case a simple (but extremely fast) linear solver. Finally, we can apply the model to held-out data to evaluate its effectiveness.
This example pipeline consists of operations that are predominantly data-parallel, which implies that running at the scale of terabytes of input images is something that can be achieved easily with Spark. Our system provides fast distributed implementations of these components, provides a APIs for parameterizing and arranging them, and executes them efficiently over a cluster of machines using Spark.
It worth noting that the schematic we’ve shown above starts to look a lot like a query plan in a database system. We plan to explore using techniques from the database systems literature to automate assembly and optimization of these plans by the system, but this is future work.
The ML Pipelines project leverages Apache Spark and MLlib and provides a few key features to make the construction of large scale learning pipelines something that is within reach of academics, data scientists, and developers who are not experts in distributed systems or the implementation of machine learning algorithms. These features are:
- Pipeline Construction Framework – A DSL for the construction of pipelines that includes concepts of “Nodes” and “Pipelines”, where Nodes are data transformation steps and pipelines are a DAG of these nodes. Pipelines become objects that can be saved out and applied in real-time to new data.
- Examples Nodes – We have implemented a number of example nodes that include domain specific feature transformers (like Daisy and Hog features in image processing) general purpose transformers (like the FFT and Convolutions), as well as statistical utilities and nodes which call into machine learning algorithms provided by MLlib. While we haven’t implemented it, we point out that one “node” could be a so called deep neural network – one possible step in a production workload for predictive analytics
- Distributed Matrixes – A fast distributed linear algebra library, with several linear solvers that provide both approximate and exact solutions to large systems of linear equations. Algorithms like block coordinate descent and TSQR and knowledge of the full processing pipeline allow us to apply optimizations like late-materialization of features to scale to feature spaces that can be arbitrarily large.
- End-to-end Pipelines – We have created a number of examples that demonstrate the system working end-to-end from raw image, text, and (soon) speech data, which reproduce state-of-the art research results.
This work is part of our ongoing research efforts to simplify access to machine learning and predictive analytics at scale. Watch this space for information about an open-source preview of the software.
This concept of treating complex machine learning workflows a composition of dataflow operators is something that is coming up in a number of systems. Both scikit-learn and GraphLab have the concept of pipelines built into their system. Meanwhile, at the lab we’re working closely with the Spark community to integrate these features into a future release.