
This project is in collaboration between the office of Lt. Governor Gavin Newsom with the CITRIS Data and Democracy Initiative and the Algorithms, Machines, and People (AMP) Lab at UC Berkeley.
Californians are using smartphones to grade the state on timely issues. The “California Report Card” (CRC) is a pilot project that aims to increase public engagement with political issues and to help leaders at all levels stay informed about the changing opinions and priorities of their constituents. Anyone can participate by taking a few minutes to assign grades to the state of California on timely issues including healthcare, education, and immigrant rights. Participants are then invited to propose issues for future versions of the platform. To participate, visit:
http://californiareportcard.org/mobile

Since January, we have collected over 15 GB of user activity logs from over 9,000 participants. We use this dataset to study new algorithms and analysis methodologies for crowdsourcing. In a new paper, A Methodology for Learning, Analyzing, and Mitigating Social Influence Bias in Recommender Systems, we explore cleaning and correcting biases that can affect rating systems. Social Influence Bias is defined as the tendency for the crowd to conform (or be contrarian) upon learning opinions of others. A common practice in recommender systems, blogs, and other rating/voting systems is to show an aggregate statistic (eg. average rating of 4 stars, +10 up-votes) before participants submit a rating of their own; which is prone to Social Influence Bias.
The CRC has a novel rating interface that reveals the median grade to participants after they assign a grade of their own as an incentive. After observing the median grade, participants are allowed change their grades, and we record both the initial and final grades. This allows us to isolate the effects of Social Influence Bias, and pose this as a hypothesis testing problem. We tested the hypothesis that changed grades were significantly closer to the observed medians than ones that were not changed. We designed a non-parametric statistical significance test derived from the Wilcoxon Signed-Rank Test to evaluate whether the distribution of grade changes are consistent with Social Influence Bias. The key challenge is that rating data is discrete, multimodal, and that the median grade changed as more participants assigned grades. We concluded that indeed the CRC data suggested a statistically significant tendency for participants to regress towards the median grade. We further ran a randomized survey of 611 subjects through SurveyMonkey without the CRC rating interface and found that this result was still significant with respect to that dataset.
Earlier, in the SampleClean project pdf, we explore scalable data cleaning techniques. As online tools increasingly leverage crowdsourcing and data from people, addressing the unique “dirtiness” of this data such as Social Influence Bias and other psychological biases is an important part of its analysis. We explored building a statistical model to compensate for this bias. Suppose, we only had a dataset of final grades, potentially affected by Social Influence Bias, can we predict the initial pre-biased grades? Our statistical model is Bayesian in construction; we estimate the prior probability that a participant changed their grade conditioned on their other grades. Then if they are likely to have changed their grade (eg. > 50%), we use a polynomial regression to predict the unbiased grade. We optimize our Polynomial Regression Model with the Bayesian Information Criterion to jointly optimize over the model parameters and degree of polynomial. Our surprising result was that the bias was quite predictable and we could “mitigate” the bias in a held-out test set by 76.3%.
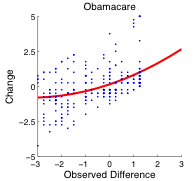
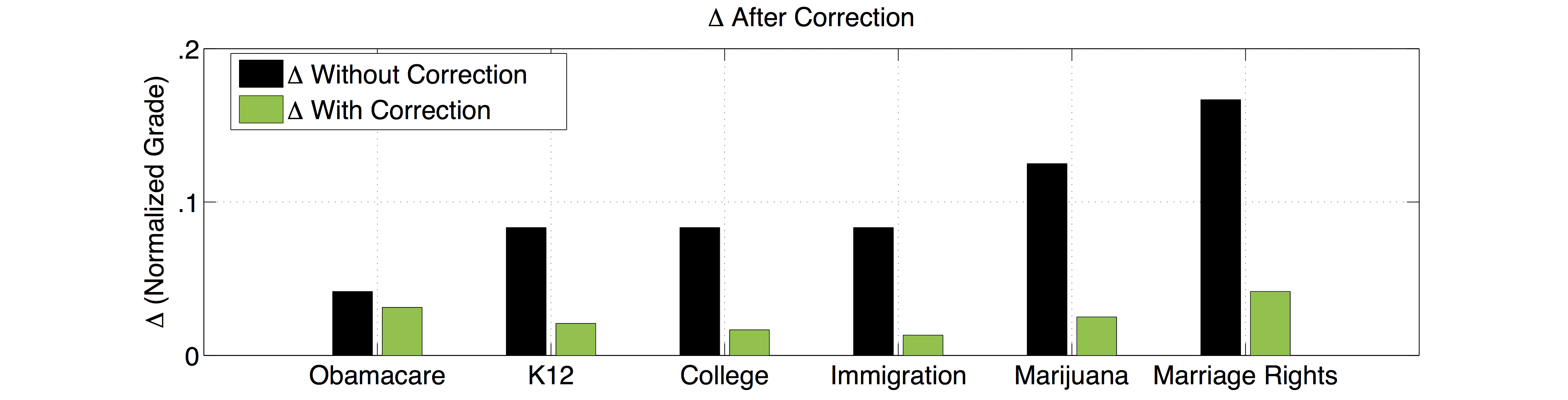
These results suggest that new interfaces and statistical machine learning techniques have potential to reduce the effects of bias in ratings-based systems such as online surveys and shopping systems. For details on the issues being graded, statistical significance, related projects, FAQ, contact info, etc, please visit the project website: http://californiareportcard.org/
[1] A Methodology for Learning, Analyzing, and Mitigating Social Influence Bias in Recommender Systems. Sanjay Krishnan, Jay Patel, Michael J. Franklin, and Ken Goldberg. To Appear: ACM Conference on Recommender Systems (RecSys). Foster City, CA, USA. Oct 2014.
[2] A Sample-and-Clean Framework for Fast and Accurate Query Processing on Dirty Data. Jiannan Wang, Sanjay Krishnan, Michael J. Franklin, Ken Goldberg, Tova Milo, Tim Kraska. ACM Special Interest Group on Management of Data (SIGMOD), Snowbird, Utah, USA. June 2014