

At the AMPLab, we are constantly looking for ways to improve the performance and user experience of large scale advanced analytics. We frequently make the fruits of our research available as open source software. Last week, we released version 0.3 of KeystoneML, a project we’ve blogged about in the past. KeystoneML is designed to simplify the construction of large scale end-to-end machine learning pipelines. For this development cycle, we focused our efforts on pipeline optimization including new features to automatically materialize intermediate reused state and cost-based selection of logical pipeline operators. In this post, we’ll recap how users can describe machine learning applications using high-level operators with KeystoneML. Then, we’ll discuss how the new features in the latest release accelerate the training of these applications.
In KeystoneML, users describe their machine learning applications as the composition of high level, modular components, which can be chained together to form complex pipeline DAGs. These components can range from general purpose statistical transformations and machine learning algorithms, to domain-specific featurization techniques (e.g., from image processing), to user-defined operations. Here’s a simple example of a text classification application specified using KeystoneML:
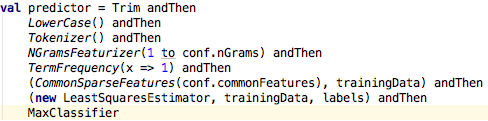
In this code snippet, a pipeline for text classification does initial pre-processing of the text using simple nodes (for example, Trim, Lowercase), converts the processed text to a vector space representation, and then fit a least squares classifier on it. Note, however, that this is an abstract definition of the classification process: the pipeline is defined independently of the actual implementation of any of its components, and the user does not need to specify how they want this application trained. This is where the KeystoneML optimizer and the new features in v0.3 come in.
Physical Operator Selection: Given the above abstract pipeline definition, one important consideration is physical operator selection. In the case of the LeastSquaresEstimator, for example, there are multiple ways to solve a linear system, and which method is best will depend on characteristics of the data (number of examples, number of features, sparsity) and the hardware (size of your cluster, how many cores, how fast is the network). In KeystoneML, a cost-based optimizer selects the appropriate physical operator to use when fitting the model based on these statistics. We refer to these kinds of optimizations as node-level optimizations.
Automatic Caching: Another class of optimizations that we have developed is whole-pipeline optimization. Given the above pipeline definition, we might use an iterative algorithm to solve the least squares problem. In this case, the algorithm will read its inputs many times before emitting a model. In this setting, it may make a lot of sense to cache the input just before the solve. But, if the input features are too big to cache fully, perhaps an earlier stage in the pipeline is an appropriate place to cache. These kinds of decisions can be tough for users to make, particularly in the face of changing workloads. Fortunately, the optimizer in KeystoneML v0.3 contains logic to automatically select which intermediate state(s) to cache.
New Operators: We’ve included a number of new Operators in this release. These include a Scala-native GMM implementation which is faster than the existing C-version for small numbers of Gaussians, a node for Image Cropping, the hashing trick for text featurization, summary information for binary classifiers, and a variety of implementations of PCA. In particular, we’ve included both local and distributed PCA implementations, as well as a distributed approximate PCA algorithm which can be significantly faster than the exact algorithm when the number of principal components requested is small relative to the number of features in the matrix.
In this post we’ve highlighted some of the new features in KeystoneML v0.3. For more information check the release notes. Also, KeystoneML v0.3 will be a focus of Mike Franklin’s keynote talk at the Strata conference on Thursday morning later this week. We are already hard at work on KeystoneML v0.4, including work on large scale kernel methods, advanced hyperparameter tuning support, and sophisticated job placement and cluster sizing algorithms. We look forward to your feedback and feature requests on Github.