
National Science Foundation
Expeditions in Computing
CURRENT PROJECTS
-

Akaros – An operating system for many-core architectures and large-scale SMP systems
-

Alluxio (formerly Tachyon), a Memory Speed Virtual Distributed Storage System
-
Cancer Tumor Genomics: Fighting the Big C with the Big D
-

CoCoA: A Framework for Distributed Optimization
-

Concurrency Control for Machine Learning
-

CrowdDB – Answering Queries with Crowdsourcing
-

DNA Processing Pipeline
-
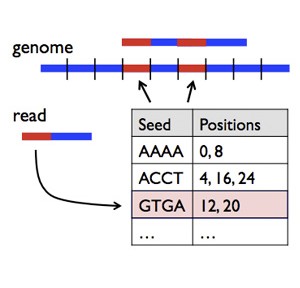
DNA Sequence Alignment with SNAP
-
GraphX: Large-Scale Graph Analytics
-

KeystoneML
-

MDCC: Multi-Data Center Consistency
-
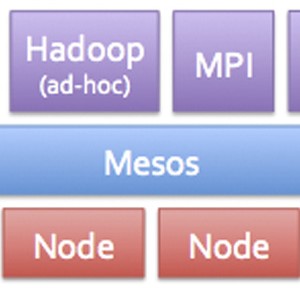
Mesos – Dynamic Resource Sharing for Clusters
-

MLbase: Distributed Machine Learning Made Easy
-
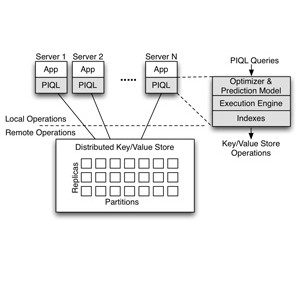
PIQL – Scale Independent Query Processing
-

Real Life Datacenter Workloads
-

SampleClean: Fast and Accurate Query Processing on Dirty Data
-
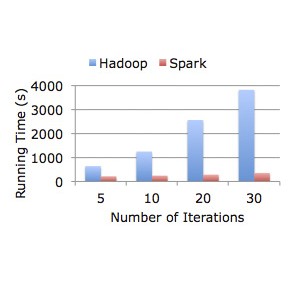
Spark – Lightning-Fast Cluster Computing
-

Sparrow: Low Latency Scheduling for Interactive Cluster Services
-

Splash: Efficient Stochastic Learning on Clusters
-

Succinct: Enabling Queries on Compressed Data
-

Velox: Models in Action
ARCHIVED PROJECTS
-

BLB: Bootstrapping Big Data
-

Carat – Collaborative Detection of Energy Bugs
-
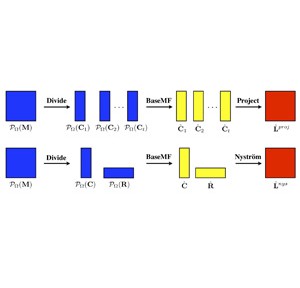
DFC — Divide-and-Conquer Matrix Factorization
-

Shark: SQL and Rich Analytics at Scale