Splash is a general framework for parallelizing stochastic learning algorithms (SGD, Gibbs sampling, etc.) on multi-node clusters. It consists of a programming interface and an execution engine. You can develop any sequential stochastic algorithm using the programming interface without considering the underlying distributed computing environment. The only requirement is that the base algorithm must be capable of processing weighted samples. The parallelization is taken care of by the execution engine and is communication efficient. Splash is built on Apache Spark and is closely integrated with the Spark ecosystem.
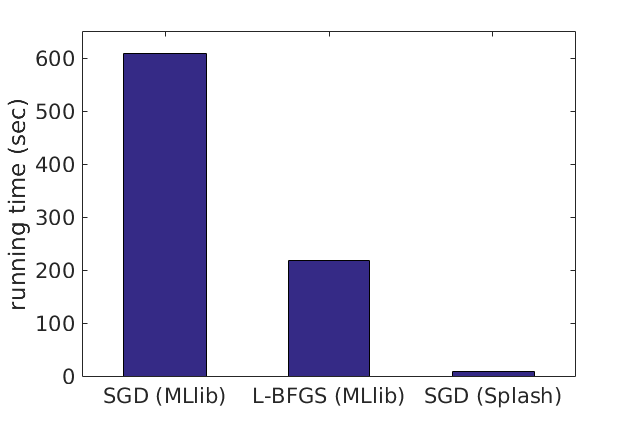
On large-scale datasets, Splash can be substantially faster than existing data analytics packages built on Apache Spark. For example, to fit a 10-class logistic regression model on the mnist8m dataset, stochastic gradient descent (SGD) implemented with Splash is 25x faster than MLlib’s L-BFGS and 75x faster than MLlib’s mini-batch SGD for achieving the same accuracy. All algorithms run on a 64-core cluster. To learn more about Splash, visit the Splash website or read our paper.