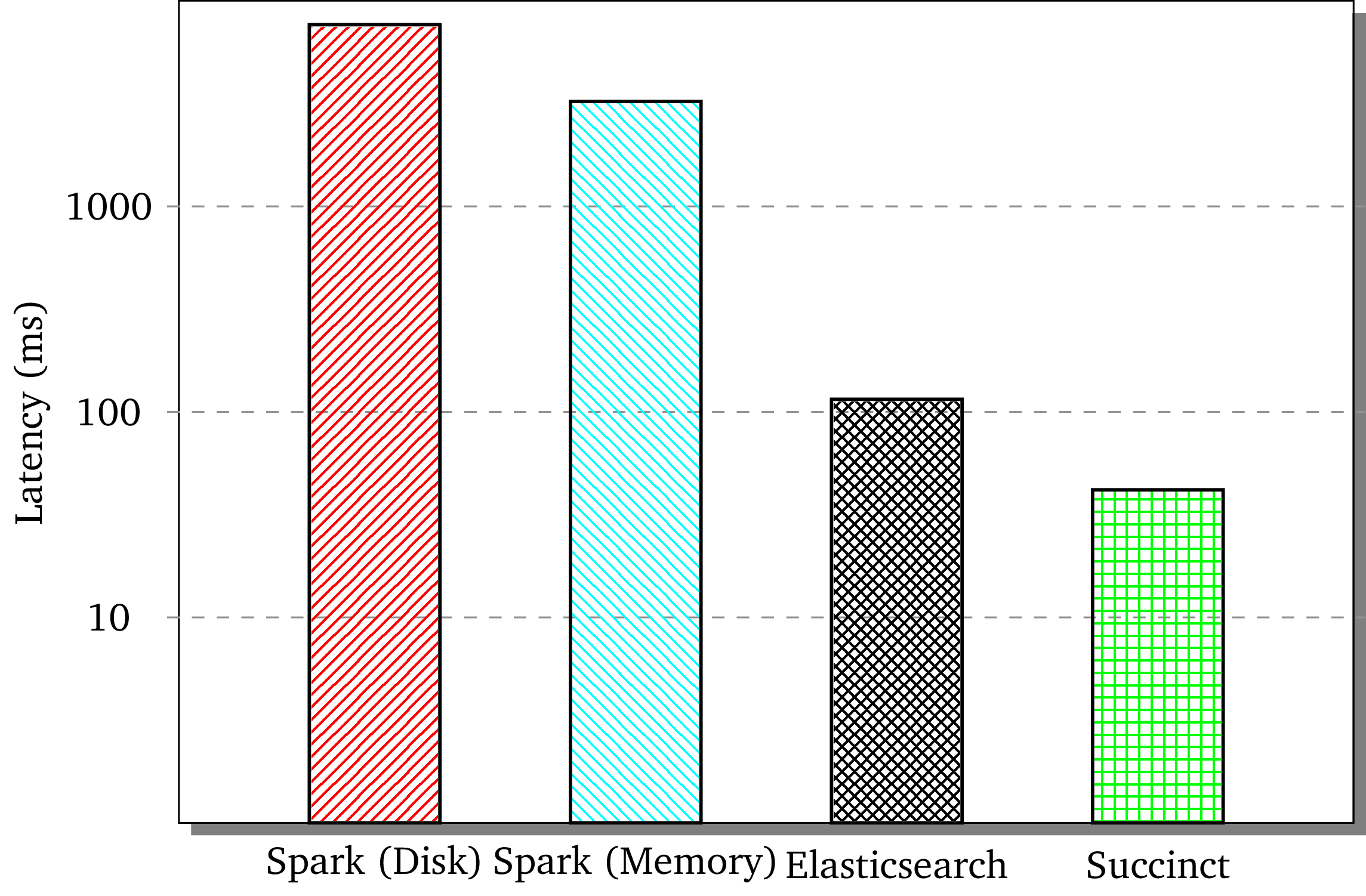
Many of the projects in the AMPLab drive systems for large-scale data analysis to ever-increasing sophistication, speed, and scale. No matter how efficient the algorithm or how powerful the system that runs it, however, the human analyst remains a fundamental in-the-loop component of a data processing pipeline. End-to-end data analysis involves frequent iteration through human-mediated processing steps such as formulating queries or machine learning workflows, enriching and cleaning data, and manually examining, visualizing, and evaluating the output of the analysis. In some of our recent work in support of the “P” in AMP, the goal is to make such operations scalable (via approximation, machine learning, and the involvement of crowd workers on platforms like Amazon’s Mechanical Turk) and low-latency (via adapting techniques inspired by the existing distributed systems literature for human workers).
One such effort focuses on data labeling, a necessary but often slow process that impedes the development of interactive systems for modern data analysis. Despite rising demand for manual data labeling, there is a surprising lack of work addressing its high and unpredictable latency. In our latest paper (which will appear in VLDB 2016), we introduce CLAMShell, a system that speeds up crowds in order to achieve consistently low-latency data labeling. We offer a taxonomy of the sources of labeling latency and study several large crowd-sourced labeling deployments to understand their empirical latency profiles. Driven by these insights, we comprehensively tackle each source of latency, both by developing novel techniques such as straggler mitigation and pool maintenance and by optimizing existing methods such as crowd retainer pools and active learning. We evaluate CLAMShell in simulation and on live workers on Amazon’s Mechanical Turk, demonstrating that our techniques can provide an order of magnitude speedup and variance reduction over existing crowdsourced labeling strategies.
A related effort looks at the problem of identifying and maintaining good, fast workers from a theoretical perspective. The CLAMShell work showed that organizing workers into pools of labelers can dramatically speed up labeling time—but how does one decide which workers should be in the pool? Because workers hired on marketplaces such as Amazon’s Mechanical Turk may vary widely in skill and speed, identifying high-quality workers is an important challenge. If we model each worker’s performance (e.g. accuracy or speed) on a task as drawn from some unknown distribution, then quickly selecting a good worker maps well onto the most biased coin problem, an interesting statistical problem that asks how many total coin flips are required to identify a “heavy” coin from an infinite bag containing both “heavy” and “light” coins. The key difficulty of this problem lies in distinguishing whether the two kinds of coins have very similar weights, or whether heavy coins are just extremely rare. In this work, we prove lower bounds on the problem complexity and develop novel algorithms to solve it, especially in the setting (like on crowdsourcing markets) where we have no a priori knowledge of the distribution of coins. Our next steps will be to run our new algorithms on crowd workers and demonstrate that we can identify good workers efficiently.
Finally, we are investigating systems for data analysis with crowdsourcing directly built in. The SampleClean project uses a combination of statistics and the crowd to support a usable data cleaning system that links crowd workers to the BDAS stack via our declarative crowd framework AMPCrowd. Our recent demo paper (in VLDB 2015) describes the system, and our most recent work focuses on data cleaning in the presence of privacy concerns. Recent advances in differential privacy make it possible to guarantee user privacy while preserving the main characteristics of the data. However, for consistent result estimation, all existing mechanisms for differential privacy assume that the underlying dataset is clean. Raw data are often dirty, and this places the burden of potentially expensive data cleaning on the data provider. In a project called PrivateClean, we explore differential privacy mechanisms that are compatible with downstream data cleaning. The database gives the analyst a randomized view of the data, which she can not only read but also modify, and PrivateClean reconciles the interaction between the randomization and data manipulation. Our work on PrivateClean is under revision for SIGMOD 2016.
In summary, the “P” in AMP is about providing experts with practical tools to make the manual parts of data analysis more efficient at scale. If you’re interested in learning more, reach out at dhaas@cs.berkeley.edu or sanjay@cs.berkeley.edu.