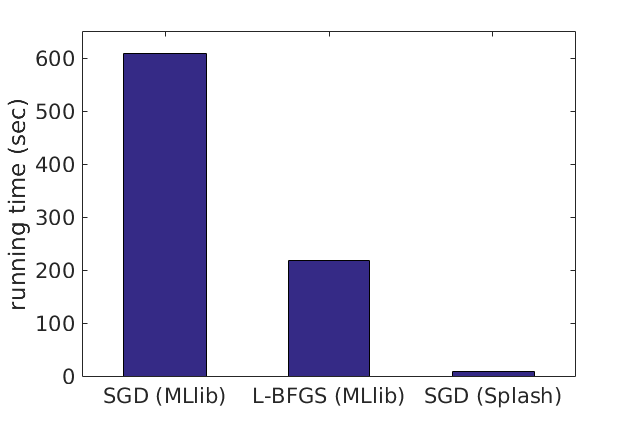
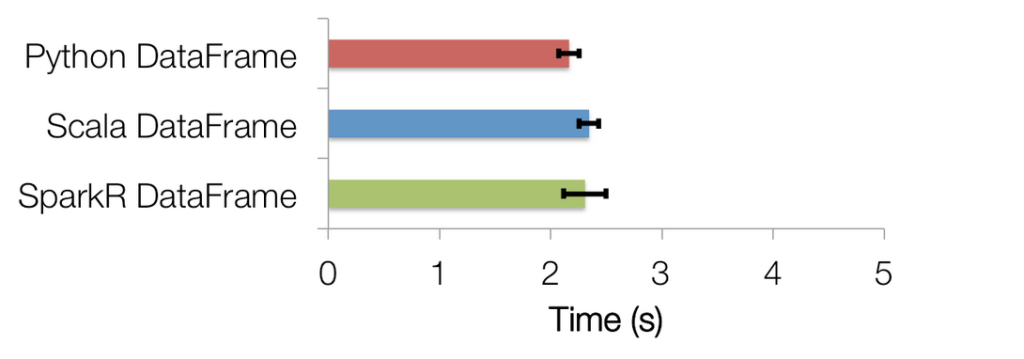
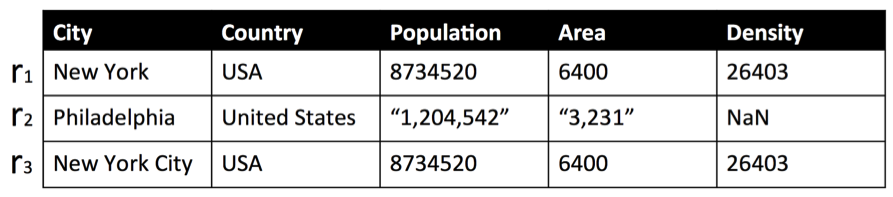
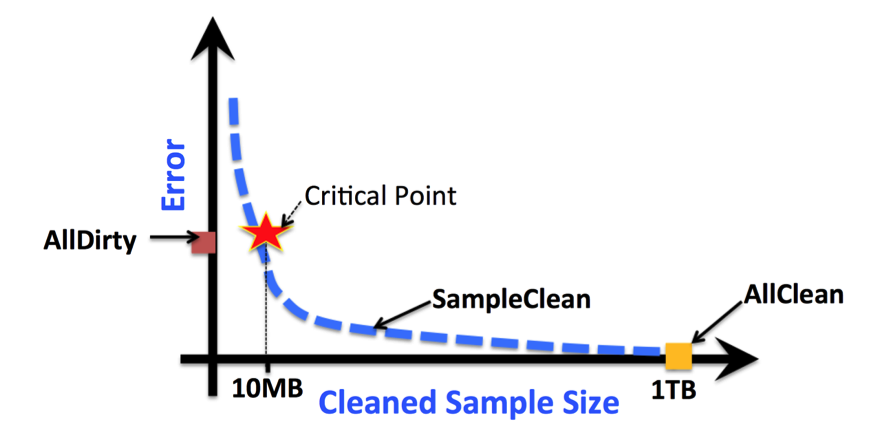
Everyone knows that many entrepreneurs went to Stanford, but few know that UC Berkeley alumni are just as entrepreneurial.
For example, many would be surprised to learn that most startups are now locating much closer to Berkeley than they are to Palo Alto. A recent article in the New York Times listed the top 50 startups worldwide likely to become the next “unicorns” (billion dollar evaluation). Impressively, not only are half of them in the Bay Area, a third are in San Francisco by itself. (The rest: New York City 8, China 4, E.U. 3, Boston 2, Chicago 2, India 2, Southern California 2, Arlington 1, and Cape Town 1.)
I thought these potential unicorns might predict where future successful startups will locate, so to see where Silicon Valley is headed, I mapped the 25 Bay Area startups and their geographic center. It looks like the next heart of Silicon Valley is San Francisco. Histories of creating regions like Silicon Valley have often pointed to the critical role of great universities. So what great technology research university is closest to San Francisco? UC Berkeley, which is just a 20-minute BART trip away.
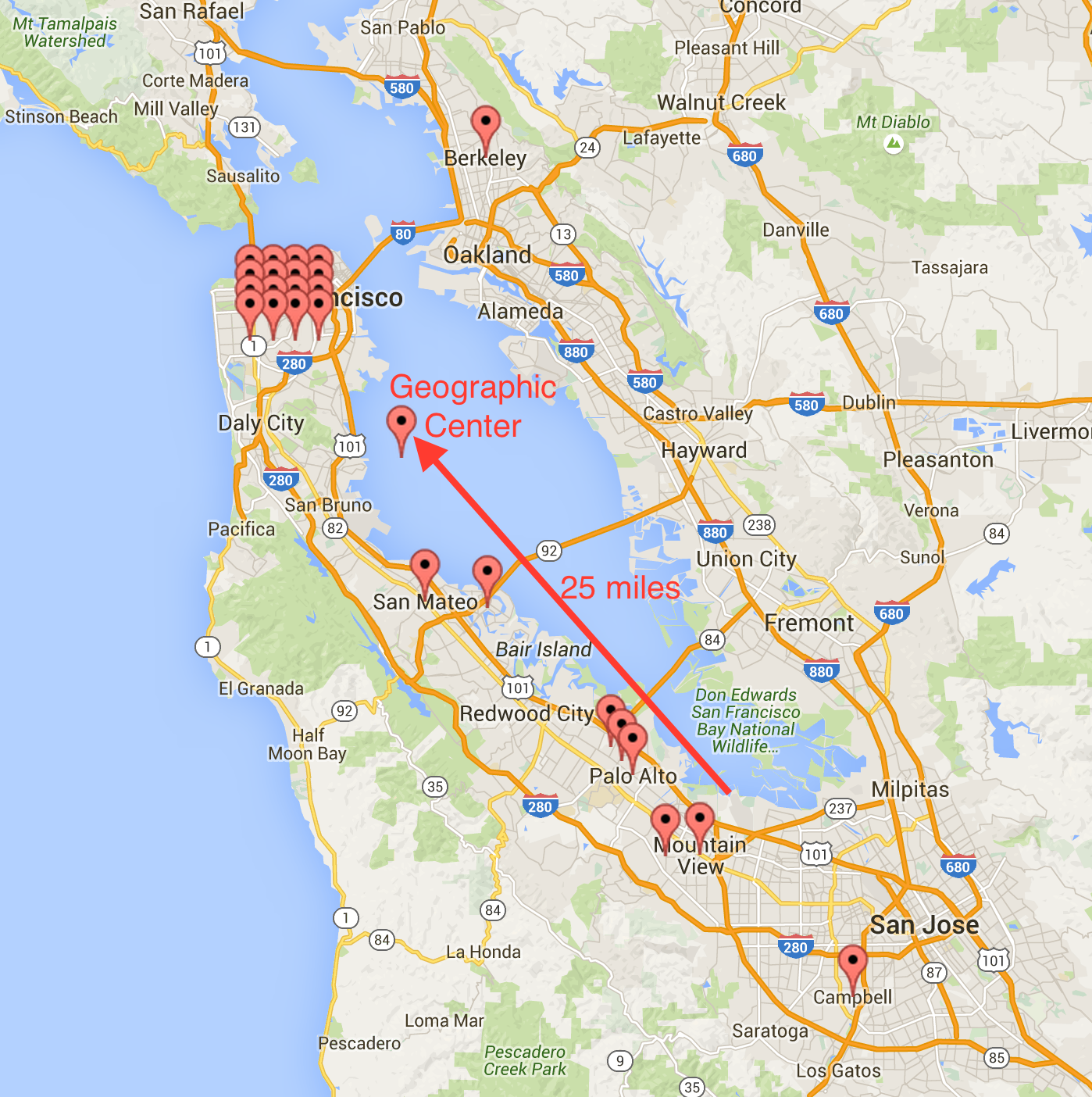
Location of 25 promising startups in the San Francisco Bay Area according to 8/23/15 NY Times